转型之路系列第2篇 | 上一篇:为什么Java工程师应该学AI? | 下一篇:Java转AI完整知识地图
目录
- 第一性原理:路径选择的底层逻辑
- 5条路径全景图
- 路径1:AI应用开发——最容易上手
- 路径2:ML工程——Java工程师的甜蜜区
- 路径3:数据工程——最平滑的过渡
- 路径4:AI基础设施——老本行升级
- 路径5:算法研究——最难但天花板最高
- 怎么选?3个决策工具
- 常见选择误区
- 总结与下一步
一、第一性原理:路径选择的底层逻辑
很多Java工程师转AI的第一步就走错了——上来就学算法、啃论文、推公式,结果3个月放弃了。
为什么会这样?因为没想清楚一个根本问题:你要转到AI的哪个位置?
用第一性原理来分析:
基本事实1:AI不是一个岗位,而是一个技术领域,里面有很多不同的岗位。
就像”互联网”不是一个岗位一样——前端、后端、运维、产品,都是互联网行业的岗位,但所需技能完全不同。
基本事实2:不同岗位对技能的要求差异极大,有的需要数学博士水平,有的只需要你会调API。
基本事实3:Java工程师已有的技能,在不同AI岗位中的”可复用度”不同。复用度越高,转型越容易。
从这三个基本事实推导出来的结论:
转型路径的选择,不是”哪个最火选哪个”,而是”我的现有技能在哪个路径上复用度最高 + 我愿意补多少新知识”。
这就是本文的核心逻辑。
二、5条路径全景图
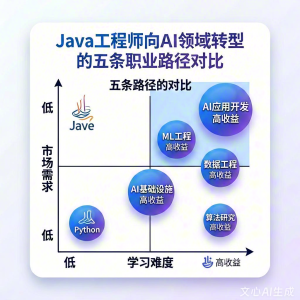
先看全貌,再逐个细讲。
| 路径 | 一句话描述 | Java技能复用度 | 学习难度 | 薪资上限 | 市场需求 |
|---|---|---|---|---|---|
| 1. AI应用开发 | 用大模型API做业务应用 | ⭐⭐⭐⭐⭐ | ⭐⭐ | 50-80K | 🔥🔥🔥🔥🔥 |
| 2. ML工程 | 把模型从notebook搬到生产 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | 50-90K | 🔥🔥🔥🔥 |
| 3. 数据工程 | 搭建AI的数据管道 | ⭐⭐⭐⭐ | ⭐⭐ | 45-75K | 🔥🔥🔥🔥 |
| 4. AI基础设施 | AI平台的架构和运维 | ⭐⭐⭐⭐ | ⭐⭐⭐ | 50-85K | 🔥🔥🔥 |
| 5. 算法研究 | 训练和优化AI模型 | ⭐⭐ | ⭐⭐⭐⭐⭐ | 60-120K | 🔥🔥🔥 |
一眼结论:对大多数Java工程师来说,路径1和路径2是最优选择——技能复用度高、学习难度可控、市场需求旺盛。
接下来逐个深入。
三、路径1:AI应用开发——最容易上手
这条路径做什么?
通俗解释:就像Java工程师用Spring Boot做后端应用一样,AI应用开发就是用大模型(GPT-4、Claude等)的API做AI应用。
你不是训练模型,你是调用模型,把它包装成业务产品。
典型工作内容:
- 开发AI聊天机器人
- 构建RAG(检索增强生成)系统,让AI回答企业内部数据的问题
- 做AI辅助的文档处理、合同审查、智能推荐
- 开发AI Agent(智能体),让AI自动完成多步骤任务
为什么最容易上手?
用第一性原理分析:AI应用开发 = 传统应用开发 + 一个新的外部服务(大模型API)
你想想,你平时调用第三方支付API、调用短信API、调用地图API——调用大模型API有什么本质区别?
几乎没区别! 大模型API就是一个更智能的外部服务。
实际代码对比:
调用支付API(你已经在做的事):
// 调用支付宝API
AlipayClient client = new DefaultAlipayClient(
"https://openapi.alipay.com/gateway.do",
appId, privateKey, "json", "UTF-8", alipayPublicKey, "RSA2"
);
AlipayTradePayRequest request = new AlipayTradePayRequest();
request.setBizContent("{"out_trade_no":"20260101001",...}");
AlipayTradePayResponse response = client.execute(request);
调用大模型API(你要学的新事):
# 调用OpenAI API
from openai import OpenAI
client = OpenAI(api_key="your-api-key")
response = client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": "帮我总结这段文字:..."}]
)
answer = response.choices[0].message.content
看出区别了吗? 流程一模一样:创建客户端 → 构建请求 → 发送请求 → 处理响应。唯一的区别是返回的结果从”支付状态”变成了”AI生成的文本”。
需要学什么?
| 技能 | 学习量 | 说明 |
|---|---|---|
| Python基础 | 1周 | 语法和Java 70%相似 |
| 大模型API调用 | 2-3天 | 就是HTTP请求 |
| Prompt Engineering | 1-2周 | 怎么写提示词让AI给出好结果 |
| RAG系统搭建 | 2-3周 | 向量数据库 + 检索 + 生成 |
| LangChain框架 | 1-2周 | AI应用开发的”Spring Boot” |
| AI Agent开发 | 2-3周 | 让AI自动规划和执行任务 |
总计学习时间:约2-3个月
完整可运行示例:一个5分钟跑起来的AI应用
以下是一个用Python + OpenAI API做的”智能问答助手”,你可以直接跑:
"""
一个最简单的AI问答应用
运行前安装依赖:pip install openai
设置环境变量:set OPENAI_API_KEY=你的API密钥
"""
from openai import OpenAI
import os
client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))
def ask_ai(question: str, context: str = "") -> str:
"""向AI提问,返回回答"""
messages = []
if context:
messages.append({"role": "system", "content": f"请根据以下背景信息回答问题:\n{context}"})
messages.append({"role": "user", "content": question})
response = client.chat.completions.create(
model="gpt-4",
messages=messages,
temperature=0.7 # 0=确定性回答,1=创造性回答
)
return response.choices[0].message.content
# 使用示例
if __name__ == "__main__":
# 示例1:直接问答
answer = ask_ai("Java和Python的主要区别是什么?用3点总结")
print("AI回答:", answer)
# 示例2:带上下文问答(这就是RAG的雏形!)
context = """
公司产品:AIDevVault - AI编程学习平台
主要功能:AI编程工具教程、AI学习路线规划
目标用户:想学AI的软件工程师
价格:免费基础版,Pro版99元/月
"""
answer = ask_ai("AIDevVault的Pro版多少钱?", context)
print("AI回答:", answer)
你看,就这么简单! 这已经是一个能用的AI应用了。当然,生产级的AI应用需要加缓存、限流、日志、异常处理——这些你都会。
适合什么人?
- 不想深入数学和算法,想快速出活
- 喜欢做产品,喜欢看到用户用你的东西
- 对后端工程比较熟,想在此基础上扩展
四、路径2:ML工程——Java工程师的甜蜜区
这条路径做什么?
通俗解释:算法科学家训练好模型(写在Jupyter Notebook里),ML工程师负责把这个模型”搬”到生产环境——让它能7×24稳定运行、能应对高并发、能自动更新。
这个角色和Java工程师的工作方式极其相似。
典型工作内容:
- 模型部署:把训练好的模型包装成API服务
- 模型服务化:构建模型推理服务的微服务架构
- 特征工程管道:搭建自动化的数据处理流水线
- 模型监控:监控模型效果是否退化
- A/B测试框架:对比新旧模型效果
为什么是Java工程师的甜蜜区?
用第一性原理分析:ML工程的核心挑战不是算法,而是工程化。
一个模型在notebook里跑得好好的,到了生产环境就出各种问题:
- 推理太慢,延迟超标 → 需要性能优化(Java工程师擅长!)
- 并发一高就崩 → 需要高并发架构(Java工程师擅长!)
- 数据格式变了,模型输入出错 → 需要数据校验(Java工程师擅长!)
- 模型效果慢慢变差 → 需要监控告警(Java工程师擅长!)
发现了吗?ML工程80%的问题,都是Java工程师日常在解决的问题。
实际例子:用Java部署一个Python模型
/**
* 一个模型推理服务:把Python训练的模型包装成REST API
* 这就是ML Engineer的典型工作之一
*/
@RestController
@RequestMapping("/api/v1/predict")
public class PredictionController {
private final ModelService modelService;
public PredictionController(ModelService modelService) {
this.modelService = modelService;
}
@PostMapping("/sentiment")
public ResponseEntity predictSentiment(
@RequestBody TextRequest request) {
// 输入校验(Java工程师的基本功)
if (request.getText() == null || request.getText().isBlank()) {
return ResponseEntity.badRequest().build();
}
// 限流检查(防止过载)
if (!rateLimiter.tryAcquire()) {
return ResponseEntity.status(429).build();
}
try {
// 调用模型推理(可能是远程调用Python服务,也可能是本地ONNX模型)
PredictionResult result = modelService.predict(request.getText());
return ResponseEntity.ok(result);
} catch (ModelInferenceException e) {
log.error("模型推理失败", e);
return ResponseEntity.internalServerError().build();
}
}
}
这就是ML工程——你的Java技能直接派上用场。
需要学什么?
| 技能 | 学习量 | 说明 |
|---|---|---|
| 机器学习基础概念 | 2-3周 | 训练、预测、评估指标 |
| Scikit-learn使用 | 1-2周 | Python最常用的ML库 |
| 模型部署工具 | 2-3周 | MLflow、BentoML、TorchServe |
| 特征工程 | 2-3周 | 数据处理、特征选择 |
| MLOps | 2-3周 | 模型版本管理、CI/CD for ML |
| 向量数据库 | 1-2周 | Milvus、Pinecone、Weaviate |
总计学习时间:约3-4个月
适合什么人?
- 喜欢工程化,喜欢让系统稳定运行
- 对微服务架构、高并发有经验
- 想做”AI和工程的交叉点”——既懂AI又懂工程
五、路径3:数据工程——最平滑的过渡
这条路径做什么?
通俗解释:AI系统需要大量数据,数据工程师负责搭建”数据管道”——把数据从各个地方采集过来、清洗干净、存储好、按时提供给AI系统使用。
一个类比你就懂了:如果AI模型是”厨师”,那数据工程师就是”采购员+配送员”。厨师再厉害,没有新鲜食材也做不出好菜。
典型工作内容:
- 设计数据仓库/数据湖
- 搭建ETL(抽取-转换-加载)管道
- 实时数据流处理
- 数据质量监控
- 数据血缘追踪
为什么是最平滑的过渡?
用第一性原理分析:数据工程的核心是”处理数据”,Java工程师每天都在处理数据。
你写SQL查数据库 → 数据工程师也写SQL
你用Redis缓存数据 → 数据工程师也用Redis/Kafka
你做数据迁移 → 数据工程师做ETL
你优化SQL性能 → 数据工程师也优化SQL性能
技能重叠度高达70%!
实际例子:一个简单的数据管道
"""
一个简单的ETL管道:从MySQL抽取数据,处理后存入数据仓库
这就是数据工程师的日常工作
运行前安装依赖:pip install pandas sqlalchemy pymysql
"""
import pandas as pd
from sqlalchemy import create_engine
# 1. Extract:从MySQL抽取数据
mysql_engine = create_engine("mysql+pymysql://user:pass@localhost:3306/ecommerce")
df_orders = pd.read_sql("SELECT * FROM orders WHERE date >= '2026-01-01'", mysql_engine)
# 2. Transform:数据清洗和转换
# 这和你在Java里写的数据处理逻辑一样,只是用Pandas写更简洁
df_orders["order_date"] = pd.to_datetime(df_orders["order_date"])
df_orders["amount"] = df_orders["amount"].fillna(0) # 空值处理
df_orders["user_segment"] = df_orders["total_purchase"].apply(
lambda x: "高价值" if x > 10000 else "普通" if x > 1000 else "低价值"
)
# 聚合统计(相当于SQL的GROUP BY)
daily_stats = df_orders.groupby("order_date").agg(
order_count=("order_id", "count"),
total_amount=("amount", "sum"),
avg_amount=("amount", "mean")
).reset_index()
# 3. Load:存入数据仓库
warehouse_engine = create_engine("mysql+pymysql://user:pass@localhost:3306/data_warehouse")
daily_stats.to_sql("daily_order_stats", warehouse_engine,
if_exists="append", index=False)
print(f"处理完成!今日新增 {len(daily_stats)} 条统计记录")
需要学什么?
| 技能 | 学习量 | 说明 |
|---|---|---|
| Python数据处理 | 1-2周 | Pandas = Python版SQL |
| 数据仓库概念 | 1-2周 | 星型模型、维度建模 |
| ETL工具 | 2-3周 | Apache Airflow、dbt |
| 流处理 | 2-3周 | Kafka、Flink |
| 数据湖 | 1-2周 | Delta Lake、Iceberg |
总计学习时间:约2-3个月
适合什么人?
- SQL写得溜,对数据处理有兴趣
- 不想直接做AI模型,但想进入AI数据链路
- 想以最快速度转型(学习曲线最平缓)
六、路径4:AI基础设施——老本行升级
这条路径做什么?
通俗解释:AI模型训练和推理需要大量的计算资源(GPU服务器),AI基础设施工程师负责搭建和管理这些计算平台——就像你以前管Java服务器一样,只是现在管的是GPU服务器。
典型工作内容:
- GPU集群管理和调度
- 模型推理服务的基础架构
- AI平台的Kubernetes部署
- 训练任务的资源调度
- 模型服务的自动扩缩容
为什么是”老本行升级”?
用第一性原理分析:AI基础设施 = 传统基础设施 + GPU调度 + 模型服务化
你已经会的东西:
- Linux服务器管理 → AI平台也需要
- Docker/K8s → AI平台也用
- 微服务架构 → 模型服务化就是微服务
- 监控告警 → AI平台也需要
- CI/CD → 模型也需要CI/CD
新增要学的:
- GPU调度和CUDA基础
- 模型推理优化(量化、剪枝、蒸馏)
- 训练框架(PyTorch Distributed、DeepSpeed)
实际例子:用Docker部署一个模型服务
# docker-compose.yml:部署一个模型推理服务
# 这和你平时部署Java应用的docker-compose几乎一样
version: '3.8'
services:
model-server:
image: pytorch/torchserve:latest-gpu
ports:
- "8080:8080" # 推理API
- "8081:8081" # 管理API
volumes:
- ./model-store:/home/model-server/model-store
deploy:
resources:
reservations:
devices:
- capabilities: ["gpu"] # 需要GPU
environment:
- TS_CONFIG=/home/model-server/config.properties
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8081/ping"]
interval: 30s
timeout: 10s
retries: 3
# 限流网关(和Java应用的架构一样)
gateway:
image: nginx:alpine
ports:
- "80:80"
volumes:
- ./nginx.conf:/etc/nginx/nginx.conf
depends_on:
- model-server
看到没?Docker、Nginx、健康检查——全是你的老本行。
适合什么人?
- 对运维、基础设施有经验
- 不想写太多业务代码
- 对K8s、Docker比较熟
七、路径5:算法研究——最难但天花板最高
这条路径做什么?
通俗解释:设计新的AI模型架构、优化训练方法、研究新的算法。这就是大家印象中”搞AI”的工作。
典型工作内容:
- 设计新的神经网络架构
- 优化模型训练方法
- 研究新的预训练策略
- 发论文、做实验
- 在特定任务上刷榜(SOTA)
为什么最难?
用第一性原理分析:算法研究的入门门槛 = 扎实的数学基础 + 深入的领域知识 + 科研能力
这三个条件,对于没有相关背景的Java工程师来说,每一个都是大坎:
- 数学基础:线性代数、概率论、微积分、优化理论——不是会算就行,要能推导、能创新
- 领域知识:你要读大量论文、理解前沿方法、知道别人做了什么
- 科研能力:发现问题、设计实验、验证假设——这和写业务代码完全不同
一个真实对比:
路径1(AI应用开发)写一个AI客服:
# 3天就能做出一个可用的版本
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": user_question}]
)
路径5(算法研究)优化一个模型:
# 需要3个月甚至更久
# 1. 读50篇论文理解现有方法
# 2. 设计新的注意力机制
# 3. 写几百行训练代码
# 4. 在8块A100上训练2周
# 5. 发现效果不如基线...
# 6. 重新来过
但是,如果你真的热爱研究,愿意投入1-2年时间补基础,这条路的天花板确实最高——顶级AI研究人员的薪资在100万以上。
适合什么人?
- 数学功底好,本科/研究生学的就是数学或相关专业
- 对科研有热情,不怕长期看不到成果
- 愿意投入1-2年补基础
对大多数Java工程师的建议:先把路径1-2走通,有了AI实践经验后,如果发现自己对算法有热情,再转向路径5。这样不会饿肚子,也有更清晰的方向感。
八、怎么选?3个决策工具
工具1:技能复用度矩阵

画出你现有技能在每条路径上的复用程度:
| 你已有的技能 | AI应用开发 | ML工程 | 数据工程 | AI基础设施 | 算法研究 |
|---|---|---|---|---|---|
| Java/Spring | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐ |
| 系统设计 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐ |
| SQL/数据库 | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐ |
| 微服务架构 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐ |
| 性能优化 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐ |
| DevOps | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐ |
选择原则:复用度越高的路径,转型成本越低。
工具2:ROI计算器
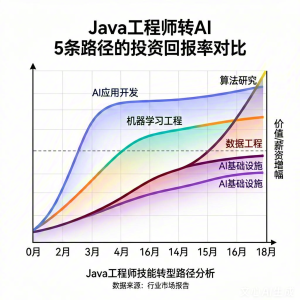
计算每条路径的投资回报率:
ROI = 薪资增幅 / 学习时间投入
| 路径 | 预计学习时间 | 薪资增幅(月) | ROI(月) |
|---|---|---|---|
| AI应用开发 | 2-3个月 | +10-20K | 5-7K/月 |
| ML工程 | 3-4个月 | +15-25K | 4-6K/月 |
| 数据工程 | 2-3个月 | +10-15K | 4-5K/月 |
| AI基础设施 | 3-4个月 | +10-20K | 3-5K/月 |
| 算法研究 | 12-18个月 | +20-40K | 1.5-2K/月 |
结论:从ROI看,AI应用开发和ML工程是性价比最高的选择。
工具3:3个灵魂问题
不用复杂的分析,问自己3个问题:
问题1:你更喜欢做什么?
- 做产品、看用户用 → AI应用开发
- 做工程、保证系统稳定 → ML工程
- 处理数据、找规律 → 数据工程
- 管基础设施、调优 → AI基础设施
- 研究算法、发论文 → 算法研究
问题2:你愿意花多少时间学习?
- 2-3个月 → AI应用开发、数据工程
- 3-4个月 → ML工程、AI基础设施
- 1-2年 → 算法研究
问题3:你接受多少不确定性?
- 想稳定转型 → 数据工程(最稳)
- 想平衡风险和收益 → AI应用开发、ML工程
- 愿意赌一把 → 算法研究
九、常见选择误区
误区1:”算法研究才是真正的AI”
第一性原理拆解:AI的价值在于”解决实际问题”,不是”做研究”。
打个比方:制药公司里,研究新药分子的科学家重要,但把药做出来、卖出去的人同样重要——而且后者更多、更赚钱。
AI应用开发、ML工程、数据工程,都是AI产业不可或缺的环节。不是做算法才叫”做AI”。
误区2:”先学算法,再学应用”
第一性原理拆解:学习路径应该从易到难,而不是从”看起来更厉害”开始。
就像学Java,你是先学JVM底层原理还是先写Hello World?肯定是先写代码跑起来,有了感性认识再深入原理。
正确顺序:先做AI应用(调用API) → 再学ML基础 → 最后按需深入算法。这样每一步都有成就感,不会放弃。
误区3:”只能选一条路”
第一性原理拆解:路径不是互斥的,可以组合。
最常见的成功路径是:先走路径1(AI应用开发),积累了实战经验后,再扩展到路径2(ML工程)。
这两个路径本身就高度重叠——做AI应用一定会碰到模型部署的问题,做ML工程也需要理解AI应用的架构。
十、总结与下一步
核心结论
用第一性原理,我们得出了3个关键结论:
- 路径选择的核心逻辑是”技能复用度”:不是哪个最火选哪个,而是你的Java技能在哪个路径上最能发挥作用
- 大多数Java工程师的最优路径是”AI应用开发→ML工程”:技能复用度高、学习难度可控、市场需求旺盛、ROI最高
- 路径不是定死的:先从最容易的路径1入手,有了实战经验再扩展,是最稳妥的策略
5条路径一句话总结
| 路径 | 一句话 |
|---|---|
| AI应用开发 | 最快上手,2-3个月出成果,适合想做产品的人 |
| ML工程 | Java工程师的甜蜜区,工程能力直接变现 |
| 数据工程 | 最平滑过渡,SQL高手的最佳选择 |
| AI基础设施 | 老本行升级,运维/DevOps工程师的AI入口 |
| 算法研究 | 天花板最高但门槛也最高,建议有了基础再考虑 |
下一步
本系列第3篇将给出完整的知识地图,告诉你具体每条路径需要学什么、按什么顺序学、用什么资源学。
- 第3篇:Java工程师转AI需要学什么?完整知识地图
📍 转型之路系列导航:
上一篇:为什么Java工程师应该学AI? | 下一篇:Java转AI完整知识地图 | 系列目录:转型之路-Java软件工程师转AI